
Soraの概要
OpenAIの新モデル「Sora」は、テキストからビデオを生成する画期的な技術です。ユーザーが入力した文章をから、動きのあるキャラクターや複雑な環境、細かい動作まで描写した最大1分間のビデオを生成することが可能になります。
また人や動物以外にも、景色などをプロンプトをベースに再現・生成することが可能です。
静止画からの生成や、動画の背景を差し替えるなどの一部の編集も対応可能なため非常に活用用途が高くなることが期待されます。
元々動画生成の文脈では、ニューヨークのスタートアップ企業Runwayが提供するGen-2モデルがあり、動画制作プロジェクトのためのAIツールとインフラを提供しています。アーティスト、デザイナー、開発者が直感的なインターフェースを通じてAIを活用し制作活動を支援すると期待されています。しかし、生成される動画が短く10〜15秒以下の生成に留まっていました。
また、OpenAIに対抗するGoogleの生成AI領域において、2024年2月8日の時点で現行モデルのAIチャットサービスであるBardからGeminiに刷新するリリースをだしましたが、そのタイミングに合わせてOpenAI側も「Sora」をリリースしました。(一般公開はまだ未定です。)
実際にOpenAI Sora生成されているサンプルを紹介します。
出典:OpenAI Sora
 okao
okao技術的な側面
Soraを分析した論文から仕組みを掘り下げていきます。
出典
タイトル:Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
URL:https://arxiv.org/abs/2402.17177
機関:Lehigh University, Microsoft Research
著者:Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, Lichao Sun
特徴は視覚的な一貫性が担保されていること
Soraの一番の特徴は、人間の複雑な指示を正確に理解し実行する能力を持っていることだと言われています。このモデルは、複数のキャラクターが複雑な背景の中で特定の動作をするような詳細なシーンを生成することができます。ユーザーが入力したテキストの指示のにとどまらず、シナリオ内の要素間の複雑な相互作用(例えば光の反射など)を把握した上で生成できるためクオリティーが高いと考えられます。
視覚的な違和感を感じないよう一貫性を保ちながらを、最大1分間の動画を生成できるも非常に面白いポイントです。従来の手法では短い動画しか生成できなかったのですが、Soraが生成する1分間の動画には、最初のフレームから最後のフレームまで、一貫した物語の流れを感じさせる視覚的な連続性があります。さらに、動作やキャラクター間の微細な相互作用を含む長時間の動画シーケンスを生成できる能力が進歩した点と言われています。

また、さまざまな長さ、解像度、アスペクト比の動画や画像を、そのまま学習し生成できることも視覚的な一貫性を担保することにつながっています。
従来の学習手法
従来の手法では、動画をすべて同じ規格(改造ウドやアスペクト比)に合わせる必要がありました。そして、規格に合わせた動画サンプルを生成し、別途トレーニングされたモデルで解像度を上げたり、フレーム補間を行います。しかし、この方法では動画全体を通して一貫性がなくなってしまいます。
Soraの学習手法
Soraは画像や動画のさまざまな規格をそのまま扱うことができるdiffusion transformerアーキテクチャを採用しています。widescreenの1920x1080pの横長動画から、1080x1920pの縦長動画まで、オリジナルの寸法を維持したまま学習と生成が可能なのです。動画の多様性を損なうことなく処理できるため動画として一貫性が保たれることを実現した、世界初のモデルなのです。
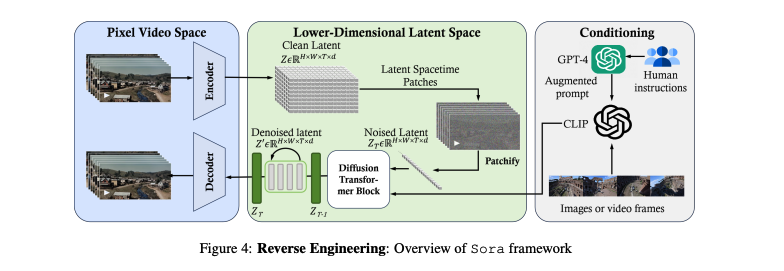
生成までの流れ
目的としては、動画の情報を圧縮し、AIが処理しやすい形式に変える。
このステップでViTが潜在表現からノイズ(不要な情報)を取り除く。
このAIがユーザーの意図を解析し、Soraに適切な動画を生成するように指示を出す。
まとめると、Soraはユーザーの指示をテキストを受け取り、それを解析し、段階を経て動画を生成するAIということですね。この仕組みには、画像や動画処理、自然言語処理など、さまざまなAI技術が組み合わされて実現できています。
今後の展開
映画制作の民主化
従来、映画の制作は製作者の経験に加えて、機材やロケーションなど、多額の費用が必要なためハードルが高いものでした。

しかし、Soraのような高度かつ人間の視覚的な違和感が少ない動画生成技術により、テキスト入力から自動的に映画を制作できる時代が到来しつつあります。Soraがストーリー性の高い映画コンテンツを手軽に生成できるようになることで、映画制作が民主化され、誰もが映画製作者になれる未来が近いうちにくるかもしれません。
教育のパーソナライズ
教育分野ではDXが進んでおらず、教科書などに頼ってきましたが、それぞれの学習者でペースや学びたい領域、理解しやすい説明など多様なニーズがあります。動画生成モデルが発展することで、教科書などの教材をカスタマイズしてダイナミックにアニメーション化できるので、学習者側の理解度とモチベーション、学習成果を大幅に高められることも期待できそうですね。

紙などの固定化された教材からパーソナライズされた動画教材へ変更できるようになれば、様々な学習スタイルに対応できるようになる可能性があります。
ゲームのリアリティーと没入感の向上
ゲームはリアリティーと没入感を高めるため様々な技術が発展してきましたが、今までのゲーム開発では事前に定義されたイベントや世界の中でしかプレイできない状況だと思います。動画生成モデルによるリアルタイムの動画生成により、世界が無限に広がる可能性もあると思います。

ゲーム内の気象や地形の変化、さらには個々のユーザーごとに拡張された新しい環境をプレイヤーの行動に応じて生成できるようになったらどうでしょうか。ゲームの世界に今までの概念を変えるぐらいダイナミックな臨場感が感じられるようになるかもしれません。ゲームの開発・プレイ・体験のあり方そのものが、イノベーションされ、新たなストーリー、没入感が提供できるようになります。
医療分野での動画活用
医療応用が期待されています。
- 細胞のアポトーシス(死滅)や皮膚病変の進行、異常な動作などの動的変化を検出し、早期発見や対策につなげられる。
- MedSegDiffV2などのモデルを用いれば、CTやMRIなど様々な医用画像からターゲット領域を高精度で抽出可能。
- Soraなどを診療現場に導入すれば、診断の精度向上に加え、解析結果に基づいた患者ごとの最適な治療計画が立案できる。
一方で、電子カルテなどの医療データの厳格な保護や、AI医療の倫理的配慮など、技術の実装においては解決すべき課題もまだまだありそうです。
ロボット分野での活用
ロボットの認識と意思決定精度を進化させる技術になるかもしれません。
- 複雑な動画を解釈・生成できるため、ロボットが環境を高度な精度で認識できるようになる
- 大規模モデルをロボットビジョンに適用することで、優れた知覚と状況理解が可能に
- 言語指示から動作結果を動画で予測できるので、ロボットが確実にタスクを実行できる
- 高品質の動画シーケンスをシミュレーション環境で生成し、実データ不足を解消

Soraなどの先進的なモデルをロボット分野に統合することで、ロボットが外部環境を適切に認識し、的確に行動できる未来も近いかもしれません。
課題と可能性
現実の物理原理と相反する生成結果が出ることもある
- 複雑なシーンにおいて、物理法則が正しく反映されないことがある
- 例えば、クッキーに噛み跡がつかない等、物理的因果関係が破綻する
- 物体の不自然な変形や、剛体(椅子など)の動きの不正確なシミュレーションが発生
- 現実的な物理的相互作用を再現できない
- 物体やキャラクター間の複雑な相互作用を正確にシミュレートできない
- 現実とかけ離れた出力になることもある
特に複雑なシーンにおいて、現実的な物体の動き、物体・キャラクター間の自然な相互関係を表現することに限界がありそうです。
空間や物体が多数あると現実味がない動画も生成される
物体やキャラクターの配置や位置関係に関する指示を誤解し、方向性(左右の区別など)がわからなくなることがあります。多数のキャラクターや要素が関係する複雑なシナリオでは、関係ない動物や人物を挿入する傾向があります。ユーザーの期待に沿った動画を生成できないケースもあります。
悪用されることのリスク
Open AIは使用上の安全性や広範囲での検証を実施しており、一般公開はまだ先です。
セキュリティ、プライバシー保護、著作権などの懸念で、まだ改善が必要な段階です。現状では最長1分間のビデオしか生成できないので一般活用できるまでにはほど遠く、まだ実験段階であると考えられます。
まとめ
okao前回、音楽の生成AIを紹介しましたが、動画の生成は業界にとって非常に大きな一歩であると思います。活用分野も多岐にわたるため、新たなビジネスが生まれていくことは間違い無いですね。しかし、同時に情報受け取るユーザーである自分たちも、正しい情報を見極める知識や姿勢が必要とされると思います。近年ディープフェイクによる事件や詐欺広告被害なども広がっているため、技術の進歩に期待しつつも、技術に飲み込まれないようにしなければなりません。
最後まで読んでいただきありがとうございました。
